Part1 从 VAE 到扩散模型
1.0 快速理解
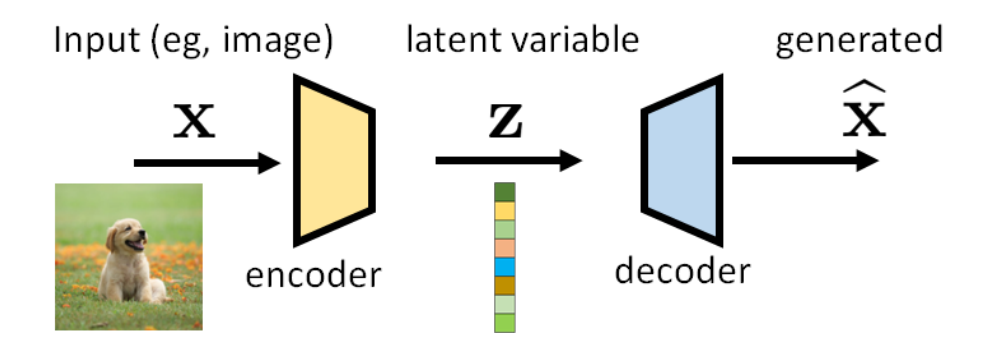
VAE的本质类似于把图片展平后(可以看做一个维度非常大的向量,如32*32*3的图(长宽深,第三个通常为rgb)展平就是个约3000维的向量)后映射(encoder)到一个维度小的向量(隐变量),然后我们再次将小的向量映射(decoder)回到大向量并还原为图片。
补充:隐变量z的要求?
答:出于简单性的考量,我们人为把隐空间控制成标准正态分布$N(0,I)$,这主要对我们的encoder提出了要求。
问:为什么需要encoder?
答:encoder主要用于辅助decoder,为decoder提供训练参考,保证一张图片经过encoder后生成的隐变量经过decoder后要尽可能还原为它自身。
1.1 为什么需要隐变量模型?
1.1.1 显式概率模型的困境
既然只是生成图片,为什么我们需要取训练一个简单分布然后映射,却不能直接学习数据分布(这里我们记作$p(x)$,x即为我们的图片,$p(x)$则为高维空间中的概率密度)如果可行的话,我们就可以直接在高维空间中采样来生成新样本 $x \sim p(x)$。
问题所在:维度爆炸下的高维稀疏性
如果我们试图直接建模 $p(x)$,即使我们使用了200000张256*256*3像素的图片,我们也只是在约20万维度的空间中填充了少量点,难以拟合出相应分布!
隐变量的动机
假设高维数据 $x$ 实际上是由低维隐变量 $z$ 通过某种确定性或随机性的映射生成的 例如:人脸图像 $x$ 可能由”姿态、光照、身份”等语义属性 $z$ 决定,那么我们就可以从一个简单的隐变量概率分布还原出真实的数据分布。
目标:$p(x) = \int p(x\mid z) p(z) dz$
因此我们理想的生成过程是
- 从先验分布采样隐变量:$z \sim p(z)$
- 通过解码器生成数据:$x \sim p_\theta(x\mid z)$(解码器由神经网络参数化)
即我们使用神经网络的似然函数改写我们的目标 \(p_\theta(x) = \int p_\theta(x\mid z) p(z) dz\)
1.2 变分自编码器 (VAE) 的数学本质
1.2.1 ELBO 的推导
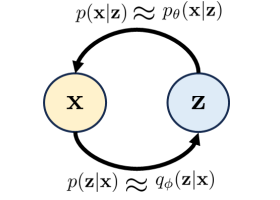
我们希望最大化对数似然 $\log p_\theta(x)$,但它包含难以计算的积分。通过引入近似后验 $q_\phi(z\mid x)$(编码器),可以推导出 ELBO:
\[\log p_{\theta}(x) = \underbrace{\mathbb{E}_{q_\phi(z\mid x)} \left[ \log \frac{p_{\theta}(x,z)}{q_\phi(z\mid x)} \right]}_{\text{ELBO (变分下界)}} + \underbrace{D_{KL}(q_\phi(z\mid x) \mid \mid p_\theta(z\mid x))}_{\text{真正的距离(不可计算)}}\]补充:为什么这里我们的损失函数是最大化似然函数?
直觉理解:我们手里有一堆真实的图片数据 ${x_1, x_2, …, x_n}$。我们希望找到一组模型参数 $\theta$,使得这组真实数据在模型分布下出现的概率 $p_\theta(x)$ 最大。
数学解释:我们的目标是让$p_\theta(x)$尽可能靠近真实数据分布$p_{data}(x)$,使用KL散度衡量这两数据分布的相似度,我们便得到\(D_{KL} = \underbrace{\int p_{data}(x) \log p_{data}(x) dx}_{\text{与 } \theta \text{ 无关的常量 (数据熵)}} - \underbrace{\int p_{data}(x) \log p_\theta(x) dx}_{\text{对数似然的期望}}\) KL散度越小说明月相近,因此我们需要最大化似然函数。
第一项:$\mathbb{E}{q\phi(z\mid x)} \left[ \log \frac{p_\theta(x,z)}{q_\phi(z\mid x)} \right]$ —— 重构项 (Reconstruction Term)
不可知,因为真实联合分布$p(x,z)$无法求解,网络自然也没法学习到$p_\theta(x,z)$(同样是高维稀疏性)
第二项:$D_{KL}(q_{\phi}(z\mid x) \mid \mid p_\theta(z\mid x))$ —— 先验匹配项
同样不可知,但由于KL散度必为正的性质,因此我们仅关注第一项的最大化(这也是”Lower Bound”的由来)
注:这里我们已经引入了encoder $q_{\phi}(z\mid x)$ 替代了真实条件概率分布,我们将其看做高斯分布(仅仅出于简单考量),而神经网络拟合的正是其分布参数(均值,方差等)decoder $p_{\theta}(x\mid z)也是同理$
1.2.2 VAE 的训练目标
前面提到真实联合概率分布$p(x,z)$不可知,因此我们采用同样办法将最大化ELBO 等价于联合优化编码器参数 $\phi$ 和解码器参数 $\theta$: \(\max_{\theta, \phi}\left[\mathbb{E}_{q_\phi(z\mid x)}[\log p_\theta(x\mid z)] - D_{KL}(q_\phi(z\mid x) \mid p(z))\right]\)
注:在Tutorial中对两次的处理并不同,从$logp(x)$到ELBO,我们是引入了$q_{\phi}$并抛弃了KL散度。而最大化ELBO中,我们则是直接使用$p_{\theta}(x\mid z)$取代了$p(x\mid z)$,此处我们是参考原论文解释,从始至终优化的目标不是$p(x)$而是$p_{\theta}(x)$
1.2.3 具体实现细节
编码器:$q_\phi(z\mid x) = \mathcal{N}(z; \mu_\phi(x), \text{diag}(\sigma_\phi^2(x)))$
输入 $x$ 经过神经网络得到均值 $\mu_\phi(x)$ 和对数方差 $\log \sigma_\phi^2(x)$并采样出$z$,那么对KL 散度就有了闭式解($q$ 是多维高斯,$p$ 是标准高斯,d为维度): \(D_{KL}(q_\phi(z\mid x) \mid \mathcal{N}(0, \mathbf{I})) = \frac{1}{2} \sum_{j=1}^{d} \left(\mu_j^2 + \sigma_j^2 - \log \sigma_j^2 - 1\right)\)
为什么预测对数方差? 神经网络输出层无界,而方差必须为正。预测 $\log \sigma^2$ 既符合模型输出特性,又避免了在计算 KL 散度时进行额外的
log运算。
通常我们假设生成误差(即真实图像 $x$ 与重建图像 $\hat{x}$ 之间的差异)服从高斯分布(同样出于简单考量):\((x - \hat{x}) \sim \mathcal{N}(0, \sigma^2_{dec}\mathbf{I}) \text{}\)
相应的解码器:$p_\theta(x\mid z) = \mathcal{N}(x; deccode_\theta(z), \sigma_{dec}^2 \mathbf{I})$
这就导致了对数似然项的公式展开:\(\log p_\theta(x\mid z) = -\frac{\| x - \text{decode}_\theta(z)\| ^2}{2\sigma^2_{dec}} - \text{Constant}\)
这里我们并没有假定$\hat{x}$的分布系数,只是推导了误差服从高斯的情况下分布损失可以转化成为$l_2$范数,因此在工程化中我们获取z往往是使用解码器分开预测两个分布参数,而获取$\hat{x}$则直接通过网络输出
1.2.4 VAE 的优缺点
优点
- 训练稳定(与 GAN 相比)
- 具有明确的概率解释
- 可以在隐空间进行插值
缺点
- 很多地方的推导都简单化。(但神奇的是确实有不错的效果)
- 生成图像模糊(由于 MSE 损失倾向于学习平均值)
- 后验坍塌(Posterior Collapse)问题:KL 项过强时,$q_\phi(z\mid x)$ 会退化为先验 $p(z)$(即不管什么图给进来都会是标准高斯),导致 $z$ 不携带任何信息,拟合完全失效
- 单层隐变量的表达能力有限
1.3 从 VAE 到层次化 VAE (Hierarchical VAE)
1.3.1 为什么需要多层隐变量?
单层 VAE 的局限在于隐变量 $z$ 需要同时编码高层语义(类别)和低层细节(纹理)。层次化结构的优势在于不同层的隐变量可以捕捉不同尺度的特征,类似于 CNN 的分层特征学习。
1.3.2 层次化 VAE 的数学形式
生成过程(自顶向下):\(z_L \sim p(z_L) \to z_{l-1} \sim p_\theta(z_{l-1} \mid z_l) \to \dots \to x \sim p_\theta(x \mid z_1)\)
推理过程(自底向上):\(q_\phi(z_1, \ldots, z_L \mid x) = \prod_{l=1}^{L} q_\phi(z_l \mid z_{l-1}, x), \quad z_0 \triangleq x\)ELBO 的扩展:\(\mathcal{L} = \mathbb{E}_{q_\phi}\left[\log p_\theta(x \mid z_1) + \sum_{l=2}^{L} \log \frac{p_\theta(z_{l-1} \mid z_l)}{q_\phi(z_{l-1} \mid z_l, x)} + \log \frac{p(z_L)}{q_\phi(z_L \mid x)}\right]\)
1.3.3 通向扩散模型的关键洞察
扩散模型可以被视为一种特殊的、具有无限层级的层次化 VAE:
推理过程能否固定?VAE 需要学习参数 $\phi$;扩散模型直接定义 $q(x_t \mid x_{t-1})$ 为固定的高斯加噪过程,去掉了变分后验的学习压力。
隐变量需要降维吗?VAE 强调压缩表征($\dim(z) \ll \dim(x)$); 扩散模型则保持维度不变($\dim(x_t) = \dim(x_0)$),通过释放维度换取更精细的细节还原能力。
如何训练生成模型?两者都最大化 ELBO。但由于扩散模型的推理过程固定,目标简化为学习唯一的变量:反向去噪过程 $p_\theta(x_{t-1} \mid x_t)$。
1.3.4 扩散模型的直观理解
正向过程(推理):逐步向数据添加噪声,最终变成纯噪声 \(x_0 \xrightarrow{q} x_1 \xrightarrow{q} \cdots \xrightarrow{q} x_T \approx \mathcal{N}(0, \mathbf{I})\)
反向过程(生成):学习逆转这个加噪过程,从噪声恢复数据 \(x_T \sim \mathcal{N}(0, \mathbf{I}) \xrightarrow{p_\theta} x_{T-1} \xrightarrow{p_\theta} \cdots \xrightarrow{p_\theta} x_0\)
核心假设:每一步的去噪过程可以用一个神经网络 $\epsilon_\theta(x_t, t)$ 来建模
1.3.5 为什么这样设计有效?
稳定的训练信号:由于正向过程是固定的,模型可以在任意时刻 $t$ 计算出 $q(x_t \mid x_0)$ 的解析形式,从而高效地采样训练数据
分而治之:将复杂的”噪声 → 数据”映射分解为 $T$ 步小的去噪步骤,每一步都相对简单
统一的网络:不同于 VAE 需要编码器和解码器,扩散模型只需要一个去噪网络 $\epsilon_\theta$,在所有时间步上共享权重